統計ソフト(仮)
統計のソフトです。
自分の学習をかねて作成してみました。
サンプルデータも同封していますので、お試し下さい。
一見すると、一郎と三郎は点の付け方が全然違うように見えます。
ところが、一郎は点の付け方が甘く、三郎は辛口ですが、傾向は似ていることがわかります。
使い方
ファイルををダウンロードした後、実行して下さい。
自己展開形式のファイルですので、実行するとファイルが展開されます。
展開されると2つのファイルが作成されます。
review.csv
サンプルデータstats.exe
プログラム本体
stats.exeを実行すると、ソフトウェアが起動します。
データを読み込みます。
「CSVファイルを開く」ボタンを押し、review.csvを開きます。
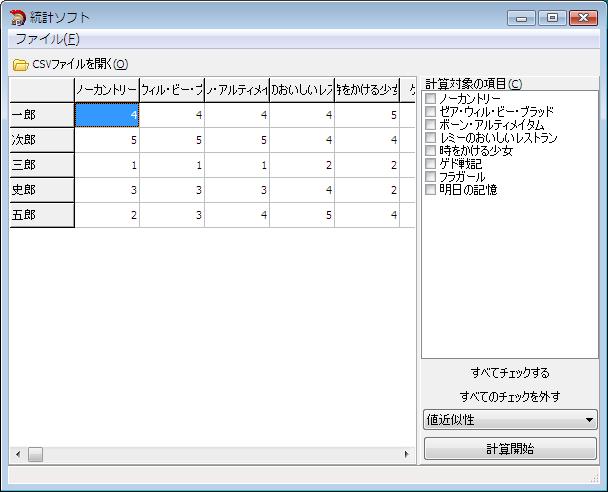
画面中央にCSVファイルのデータが表示されます。
画面右(「計算対象の項目」)には列の名前が表示されます。
「計算対象の項目」から任意の項目をチェックします。
「値近似性」が選択されている状態で、「計算開始」ボタンを押します。
選択した項目を対象に計算を行い、計算結果を表示します。
「値近似性」は、計算対象項目の各値がどれくらい近いかを計算します。
全く同じ時は「1」になり、距離が離れるほど「0」に近くなります。
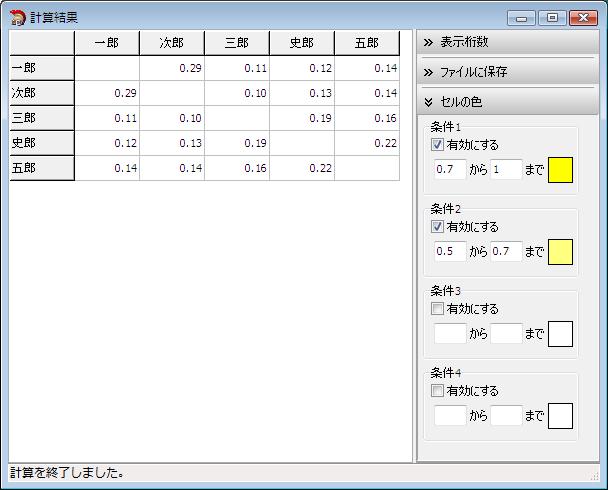
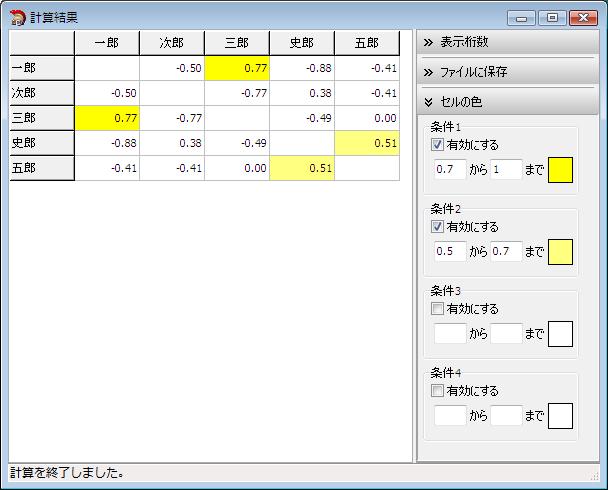
計算結果画面の表示桁数は、初期値は小数点以下2桁まで表示します。
画面右側の「表示桁数」をクリックし、バーを左右に移動することで、表示桁数を変更できます。
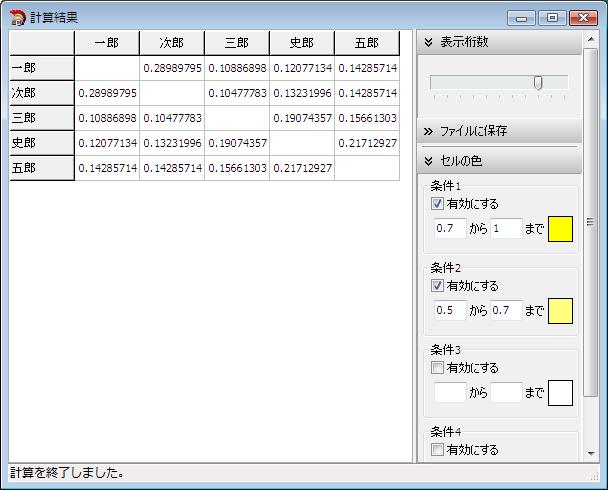
次に「傾向近似性」に進みます。
メイン画面で「傾向近似性」を選択します。
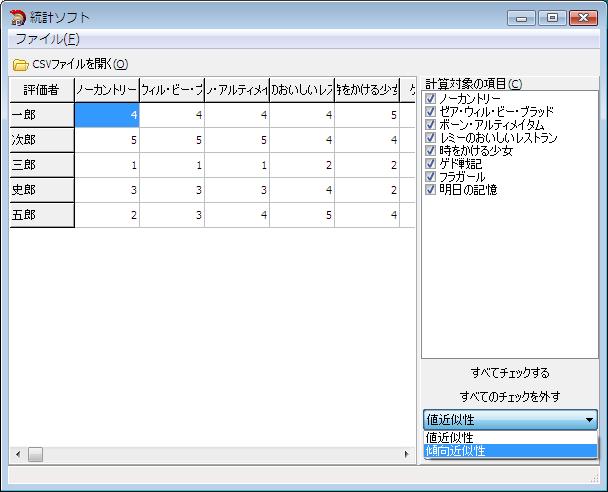
「計算開始」ボタンを押しすと、「傾向近似性」の計算を行います。
「傾向近似性」では、数値の傾向の近さを計算します。
「1」に近づくほど傾向が似ており、「-1」に近づくほど逆の傾向になります。
例えば、すべての計算対象項目をチェックして「傾向近似性」を計算した場合、 一郎と三郎は、洋画よりも邦画の方に高い点を付けているため、「傾向近似性」の結果が高い数値になります。
一郎は点の付け方が甘く、三郎は辛口ですが、傾向は似ていることがわかります。
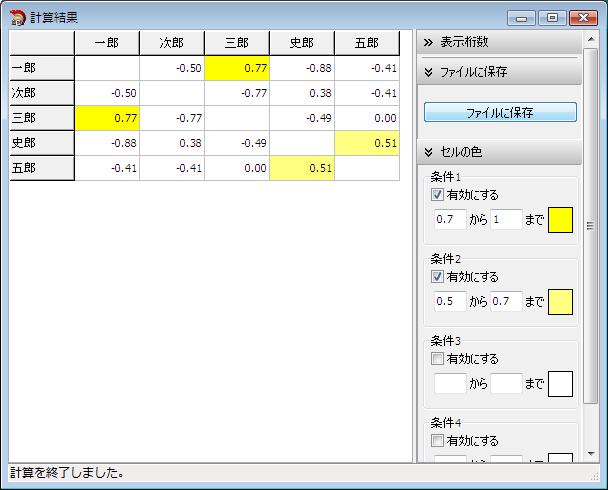
計算結果は「ファイルに保存」ボタンで、CSVファイルに保存することができます。
ダウンロード
バージョン 0.0.1
- 2008年10月5日
- 自己解凍形式
- 530 KB
- 初公開